Home
About
Services
Machine Learning
Data Analytics
Software Development
SEO
Design & Development
Digtal Marketing
Courses
AI with Python
NLP with GENAI
Agentic AI
Our Products
INVENTORY SYSTEM
OCR ENGINE
E- learning Application
Blog
Contact
Enroll
Step by Step Guide to Sentiment Analysis
4.5 Tokenization
Tokenization is use for dividing the text into a sequence of words or sentences.In below output, used only index value of 1, you can use any index.
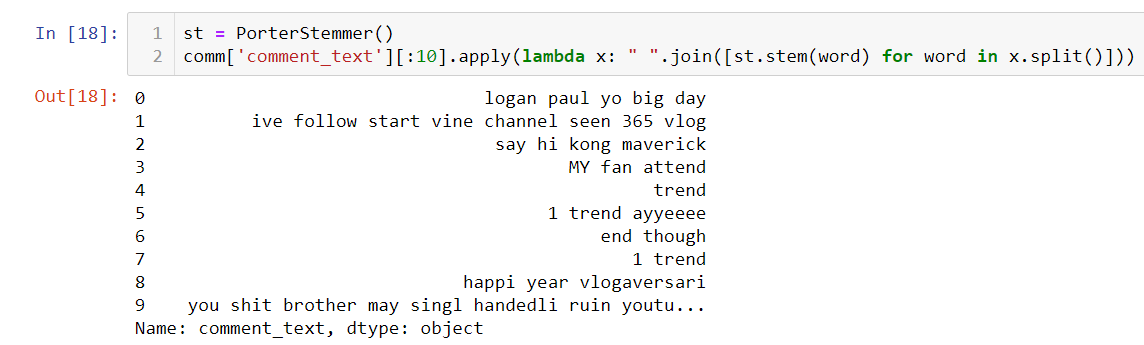
4.6 Stemming
Stemming is use for removal of suffices, like “ing”, “ional”, “ly”, “s”, etc. by a simple rule-based approach. we use PorterStemmer from the NLTK library. In below output, we can see following is follow and trending is trend.
previous
page:8 of 13
next